



12. Menü OCRKapitel hinzufügen
12.1 OCR-AttributeAbschnitt hinzufügen
Hier legen Sie in Abhängigkeit der genutzten OCR-Engine (ABBYY bzw. Tessseract) die OCR-Attribute fest, die BCS-2 zur Bearbeitung eines Images verwendet.
Globale OCR-Attribute einstellen: BCS-2 nutzt diese Konfiguration immer dann, wenn keine job- bzw. seitenspezifischen Einstellungen vorgenommen oder die OCR-Einstellungen durch den Job-Index gesteuert werden.
 OCR-Attribute für aktuellen Job einstellen: BCS-2 nutzt die Konfiguration für die OCR-Verarbeitung des aktuellen Jobs.
OCR-Attribute für aktuellen Job einstellen: BCS-2 nutzt die Konfiguration für die OCR-Verarbeitung des aktuellen Jobs.
 OCR-Attribute für aktuelle Seite einstellen: BCS-2 nutzt die Konfiguration nur für die OCR-Verarbeitung der aktuellen Seite.
OCR-Attribute für aktuelle Seite einstellen: BCS-2 nutzt die Konfiguration nur für die OCR-Verarbeitung der aktuellen Seite.
globale OCR-Attribute zurücksetzten…: BCS-2 setzt die OCR-Attribute auf die ursprünglichen Standardwerte der Anwendung zurück.
OCR-Attribute des Jobs zurücksetzen…: BCS-2 setzt die OCR-Attribute auf die globalen Einstellungen zurück.
OCR-Attribute des Images zurücksetzen…: Setzt die OCR-Attribute auf die jobspezifischen oder globalen Einstellungen zurück.
12.2 OCR-Attribute einstellenAbschnitt hinzufügen
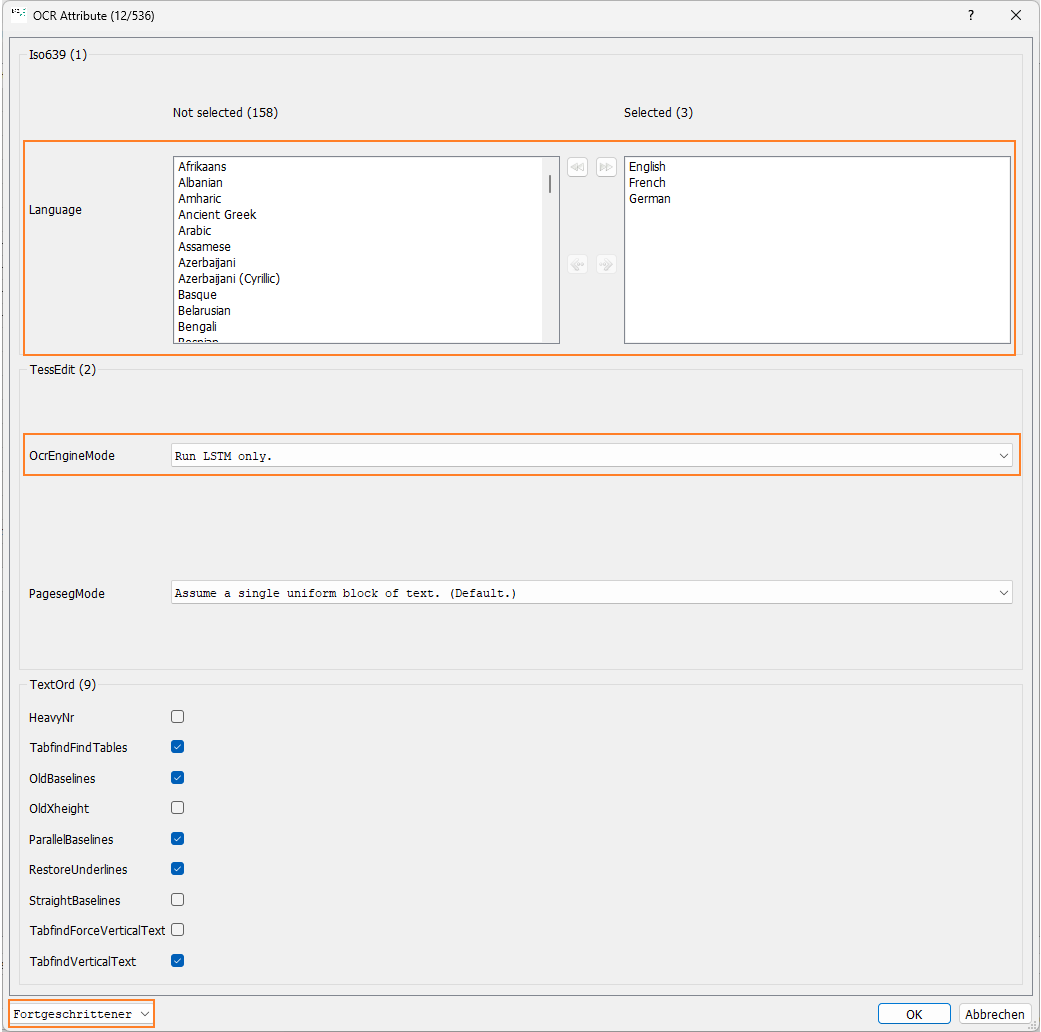
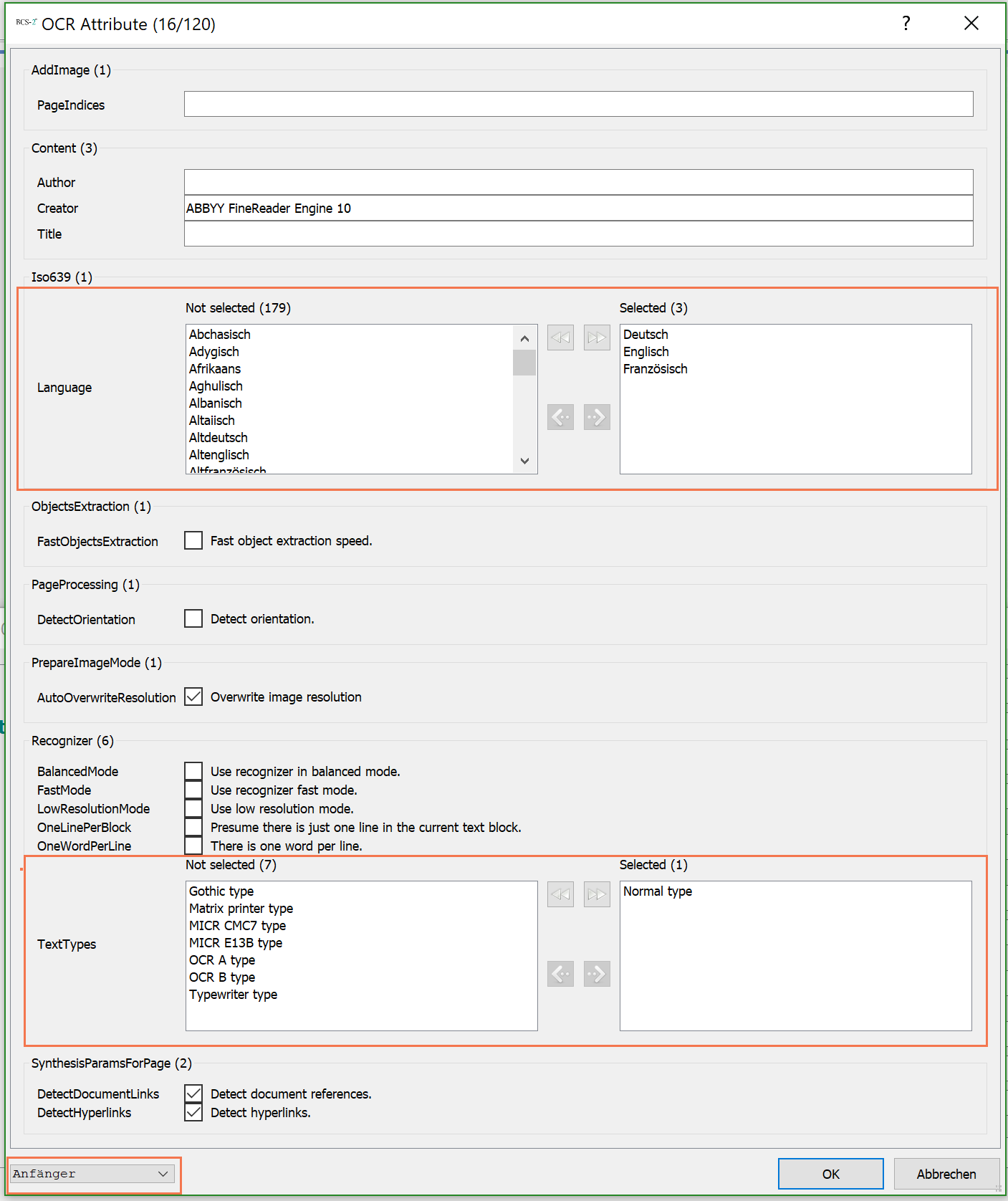
Da die OCR-Engines mannigfaltige Konfigurationsmöglichkeiten anbieten, wählen Sie über die Dropdownliste unterhalb der „OCR-Attribute“ eine Erfahrungsstufe aus (Anfänger, Fortgeschrittener, Experte). So grenzen Sie die Anzahl der Konfigurationsmöglichkeiten ein.
Die Attribute für die OCR-Engines sind vorkonfiguriert, sodass Sie meist nur noch die Sprache und im Fall von ABBYY die Schriftart bestimmen.
Wählen Sie Schrift und Sprache nicht korrekt aus, fällt das Ergebnis der OCR entsprechend schlecht aus.
{kind=link}
Tesseract
ABBYY
12.3 OCR durchführenAbschnitt hinzufügen
 OCR für markierten Bereich durchführen: BCS-2 führt die Texterkennung nur für den ausgewählten Bereich auf dem Image durch.
OCR für markierten Bereich durchführen: BCS-2 führt die Texterkennung nur für den ausgewählten Bereich auf dem Image durch.
 OCR für aktuelle Seite durchführen: BCS-2 führt die Texterkennung für die gesamte Seite durch.
OCR für aktuelle Seite durchführen: BCS-2 führt die Texterkennung für die gesamte Seite durch.
OCR für aktuelle Seite durchführen und Segmente anzeigen: BCS-2 führt die Texterkennung für die gesamte Seite durch und zeigt anschließend die von der OCR-Engine erkannten Segmente (Bereiche) an.
OCR-Text der aktuellen Seite editieren (STRG+O): Ruft den Texteditor zur Korrektur oder zum Kopieren des OCR-Volltextes auf.
12.4 Zonierte OCRAbschnitt hinzufügen
Für die direkte Übernahme von Texten in die Zwischenablage steht im Kontext-Menü des Viewers die Funktion „zonierte OCR ins Clipboard“ zur Verfügung.
Mit dieser Technik ist es einfach OCR-Daten zu erzeugen und entsprechenden Objekten (Knoten) oder Indizes zuzuweisen:
- Im Strukturbaum: Rechtsklick auf den jeweiligen Knoten und Auswahl „Text aus ClipBoard einfügen“
- Im Job-Index: Übernahme ins letzte aktive Feld
- An beliebigen Stellen: Element auswählen und mittels CONTROL-V den Text-Inhalt des Clipboards einfügen
12.5 Sprachausgabe von OCR-TextenAbschnitt hinzufügen
BCS-2 liest OCR-Texte auch vor.
An folgenden Stellen ist eine Sprachausgabe möglich:
- Zonierte OCR ins Clipboard: Drücken Sie beim Ziehen mit der Maus die STRG-Taste, anschließend liest BCS-2 den Text vor.
- OCR-Editor (OCR-Ergebnis-Dialog): Hier ist ein entsprechender Button vorhanden, der den Text-To-Speech-Dialog öffnet.
- OCR-Editor (eingeblendet): Hier ist ein entsprechender Button vorhanden, der den Text-To-Speech-Dialog öffnet
Im offenen Text-To-Speech-Dialog besteht die Möglichkeit die Sprache zu wechseln, sofern diese im jeweiligen Windows-System installiert wurde.
Ferner ist auch der Text selbst änderbar, d.h. Sie können testweise im offenen Text-To-Speech-Dialog beliebige Texte via Copy und Paste einfügen, um so z.B. anderssprachige Texte über die Sprachfunktion auszugeben.
12.6 OCR-ZusatzfunktionenAbschnitt hinzufügen
Die OCR-Zusatzfunktionen stehen erst nach einem erfolgreichen OCR-Lauf zur Verfügung.
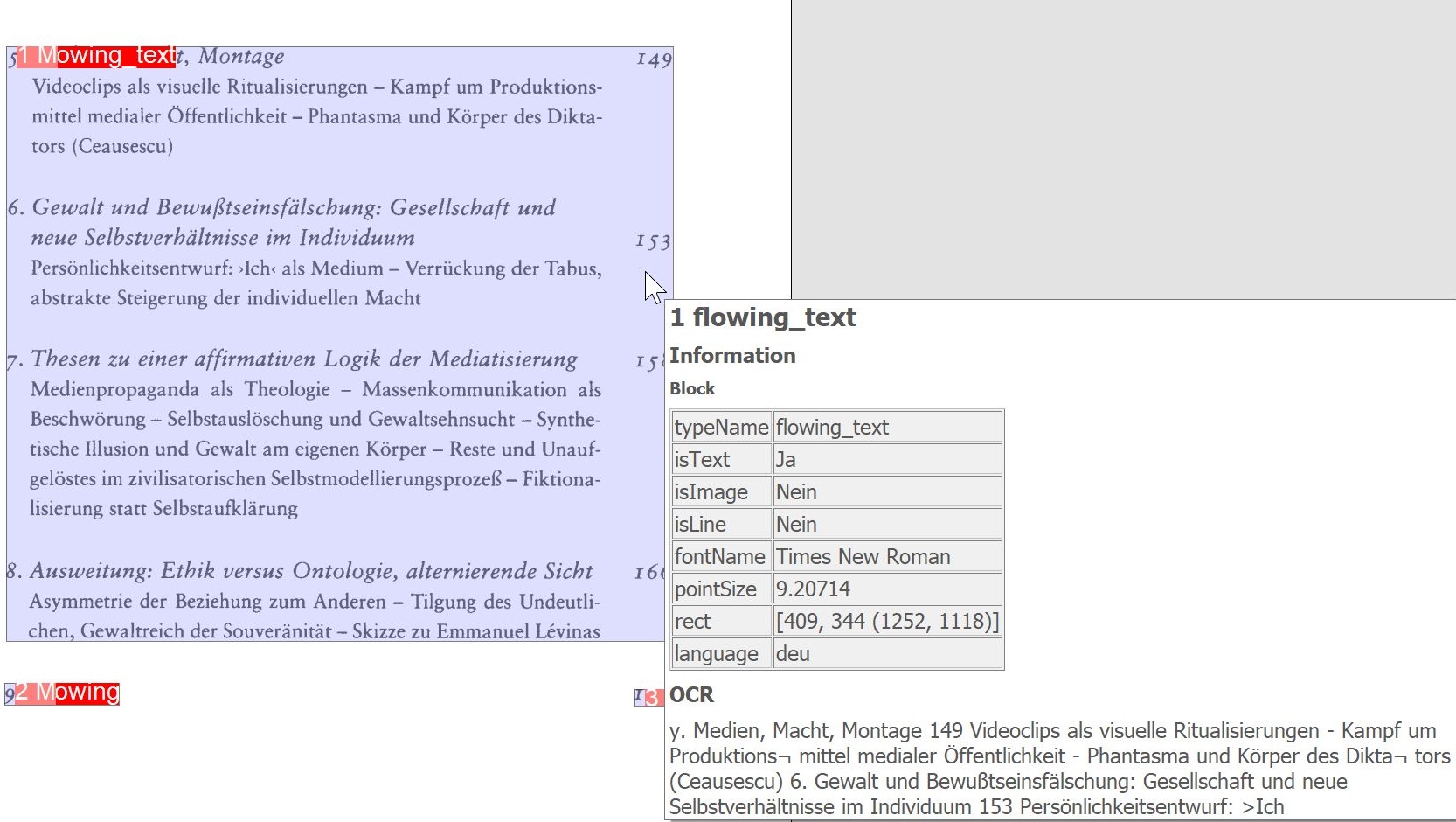
OCR-Blöcke hervorheben: Zeigt von der OCR erkannte Blöcke auf dem Image an.
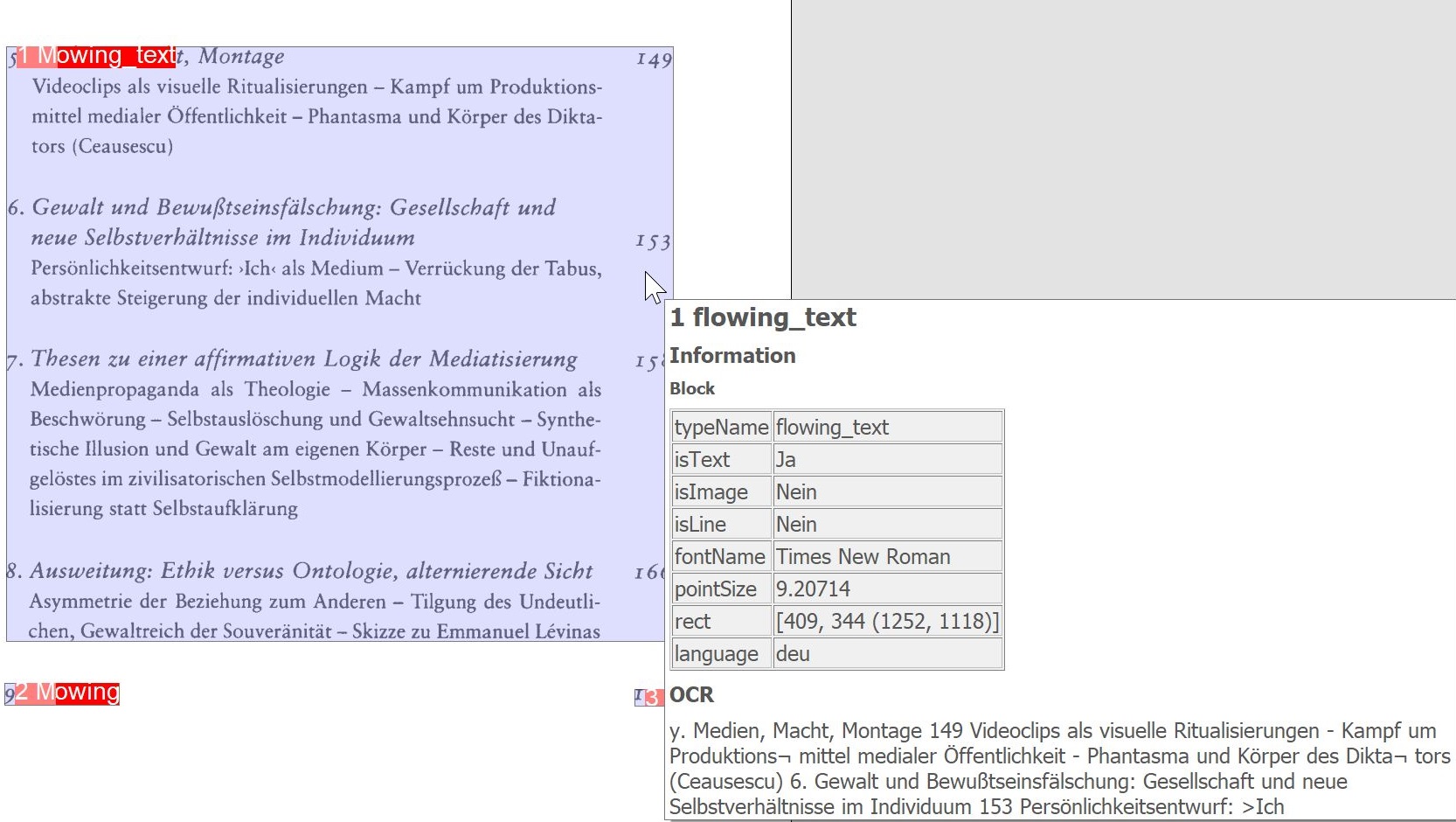
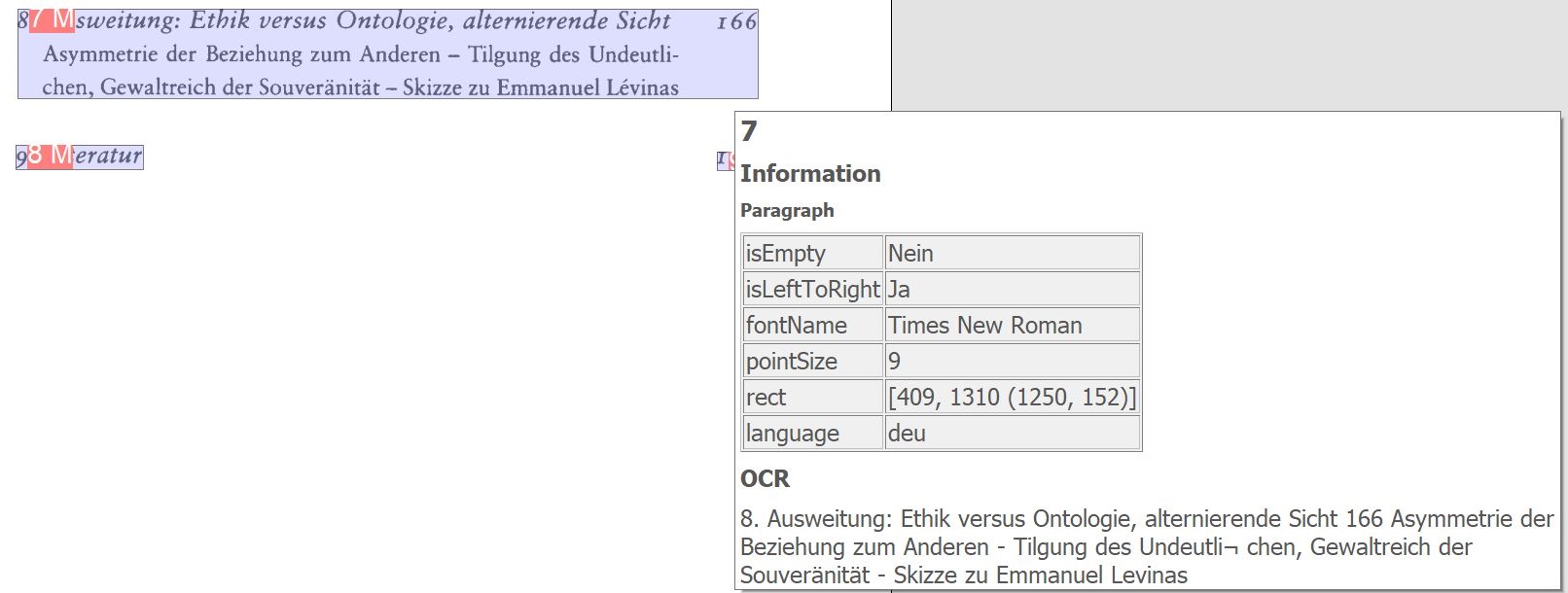
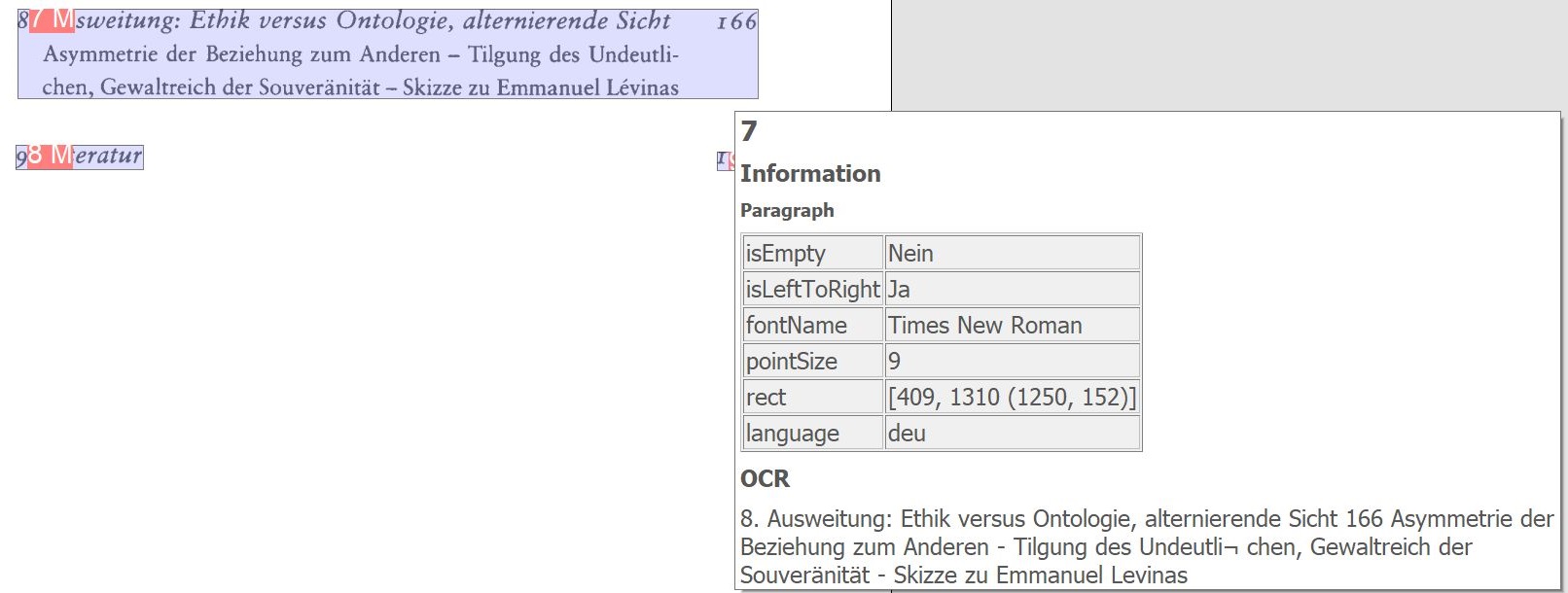
OCR-Absätze hervorheben: Zeigt von der OCR erkannte Absätze auf dem Image an.
{kind=link}
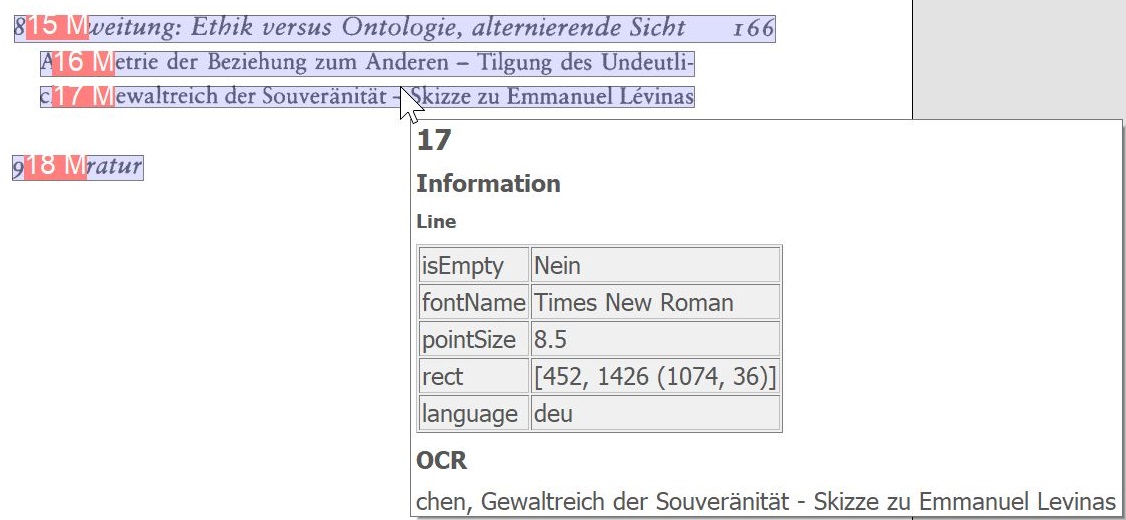
OCR-Textzeilen hervorheben: Zeigt von der OCR erkannte Textzeilen auf dem Image an.
{kind=link}
OCR-Worte hervorheben: Zeigt von der OCR erkannte Wörter an.
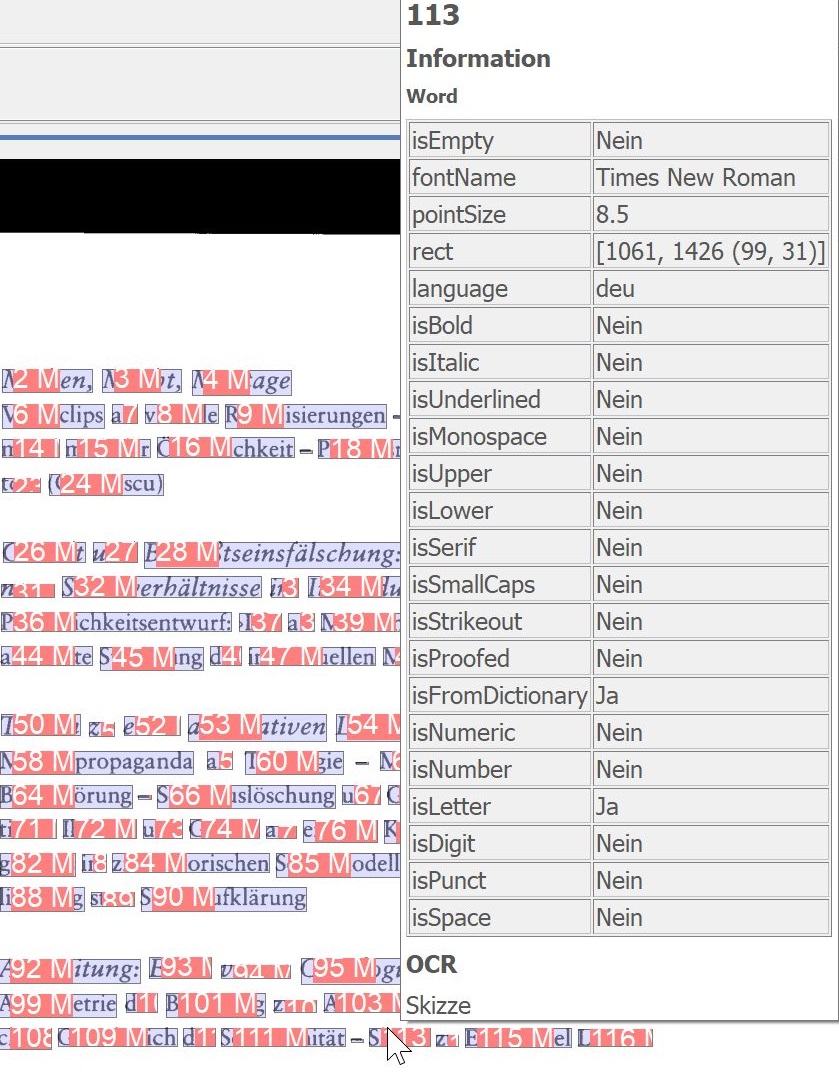
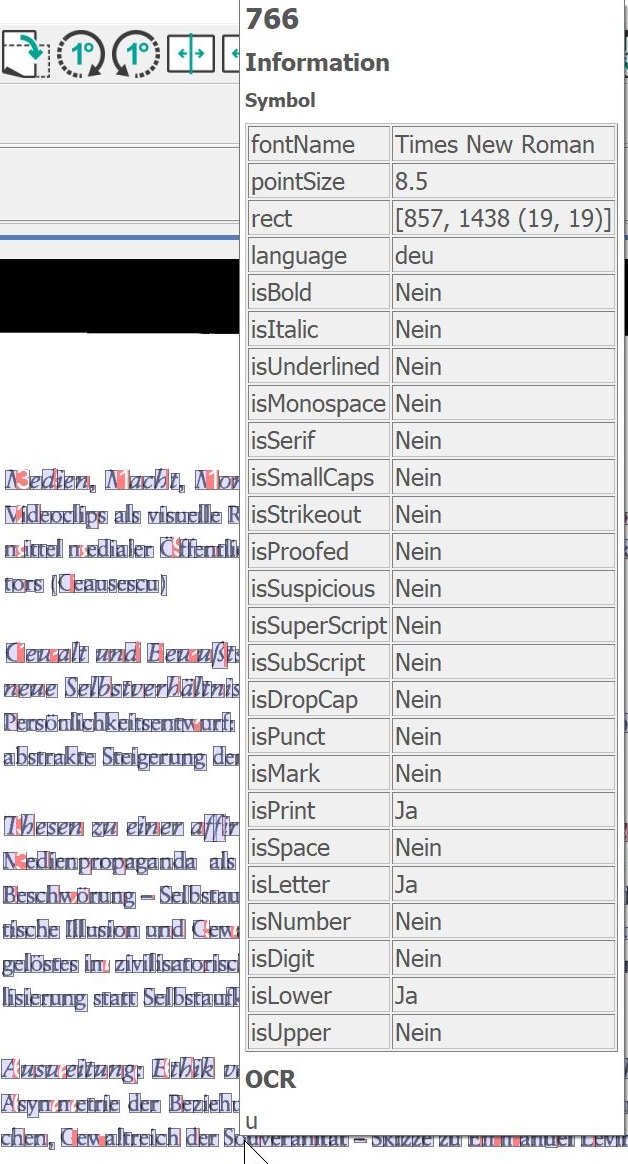
Für alle o. a. OCR-Zusatzfunktionen gilt: Bei einem Mouseover über die markierten Bereiche zeigt BCS-2 die ermittelten OCR-Informationen an.
OCR-Symbole hervorheben: Hebt alle von der OCR erkannten Symbole und Buchstaben hervor.
Suche in OCR-Texten: Voraussetzung ist, dass der OCR-Text im IWC-DOK-Format vorliegt. Bei OCR-Texten, die Sie über den Shortcut „O“ oder über das Menü „Job“ > „Operationen auf dem Job ausführen“ erzeugen, ist dies der Fall. Das Suchformular öffnen Sie über den Shortcut „strg + F“.
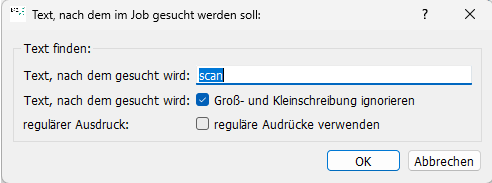
Die gefunden, passenden Einträge markiert BCS-2 in gelb:

12.7 OCR-Bearbeitung mit ABBYY von großen oder vielen JobsAbschnitt hinzufügen
Bei Nutzung der ABBYY-OCR kommt es gelegentlich zum Abbruch des OCR-Laufs und der Beendigung von BCS-2 wenn Sie gleichzeitig viele Jobs oder Jobs mit sehr großen und vielen Images bearbeiten. Ursache ist der durch die OCR-Engine nicht komplett freigegebene Speicher.
Bei kleineren (bis zu 100 Seiten) und wenigen OCR-Jobs am Tag führt dies nicht zu Einschränkungen.
Bearbeiten Sie jedoch
- große und viele OCR-Jobs,
- große Images mit Fraktur-OCR,
- oder OCR für schlechte/schwierige Vorlagen (z.B. vergilbtes Papier, verschmierter Druck, Flecken oder Mikrofilm-Scans)
kommt es gelegentlich zu Abstürzen.
Zur Vermeidung empfehlen wir:
- Schließen Sie alle anderen Programme bei der Verarbeitung solcher Jobs.
- Lassen Sie immer nur eine begrenzte Anzahl an OCR-Jobs von der Stapelverarbeitung bearbeiten. Teilen Sie große OCR-Jobs bei der Batchverarbeitung in kleine Einheiten à 100 oder 250 Seiten auf.
- Stellen Sie sicher, dass auf ihrem PC „mindestens“ die doppelte Menge des größten Jobs an Speicherplatz frei ist, damit ABBYY das Zwischenergebnis auslagern kann.
- Starten, bzw. lassen Sie BCS-2 regelmäßig neu starten.
Führen Sie häufiger datenintensive Joboperationen durch, sprechen Sie bitte unseren Support an. Zur automatischen OCR über Nacht ohne Operatoren beraten wir Sie gerne.
Generell gibt es keine Empfehlung von ABBYY zur maximalen Jobgröße. Die OCR-Engine wurde jedoch für Clients und typische Clientanwendungen entwickelt. Als Faustregel gilt, dass Jobs mit bis zu 100 Seiten störungsfrei laufen. Für datenintensive Jobs bietet ABBYY eine Serverlösung an.
12.8 OCR-Umbrüche entfernenAbschnitt hinzufügen
Erkennt die OCR Umbrüche, dann sind diese im OCR-Text für gewöhnlich auch enthalten.
Dies gilt allerdings nicht, wenn der OCR-Text nachträglich aus dem intern vorliegenden IW-OcrDoc-Objekt geholt wird:
Hier wird nur die Wortliste durchsucht und alle zu einem Bereich gehörenden Wörter werden, durch Blanks getrennt, zurückgeliefert.
Es hängt von der Art und Weise ab, wie der konkrete OCR-Text in der Anwendung beschafft wird.
Wird er durch direkte OCR, also ohne das IW-OcrDoc, geholt (durch einen direkten ABBYY-Lauf), dann sind die Umbrüche vorhanden.
ANPASSUNG ab Release 6.4.6:
- Wird ein OCR-Text aus einem Bereich mittels des Bereichs-Eigenschaften-Dialogs einem Index zugewiesen, werden Zeilenumbrüche durch Leerzeichen ersetzt.
Ein generelles Entfernen von Umbrüchen ist nicht sinnvoll.
Was kann noch getan werden:
Werden OCR-Ergebnisse in Scripts verwendet, können Sie im Script die entsprechenden Ersetzungen vornehmen:
Beispiel:
Enthält die Script-Variable „str“ eine Zeichenkette, in der auch Umbrüche sind, können diese mittels
- str.replace(„\n“, “ „)
entfernt werden.
Verwenden Sie anstelle des Ausdrucks str, str.replace(„\n“, “ „).