



2.1 Import in vorhandene AufträgeAbschnitt hinzufügen
2.1.1 Import ohne Seitenextraktion
Der manuelle Import ohne Seitenextraktion eignet sich vor allem dann, wenn das Dokument beim Ausliefern nicht verändert werden soll, beispielsweise bei Auslieferung von DRM geschützten PDF-Dateien. Dadurch wird das PDF nicht in Einzelimages zerlegt sondern so, wie es hereinkommt ausgeliefert.
Der manuelle Import erfolgt interaktiv über die Auftragsvorschau von MyBib eDoc, wobei nur PDF- und MultiTiff-Dateien importiert werden können.
Wenn Sie hierzu aus dem Einstiegsmenü heraus starten, klicken Sie auf Aufträge auflisten.
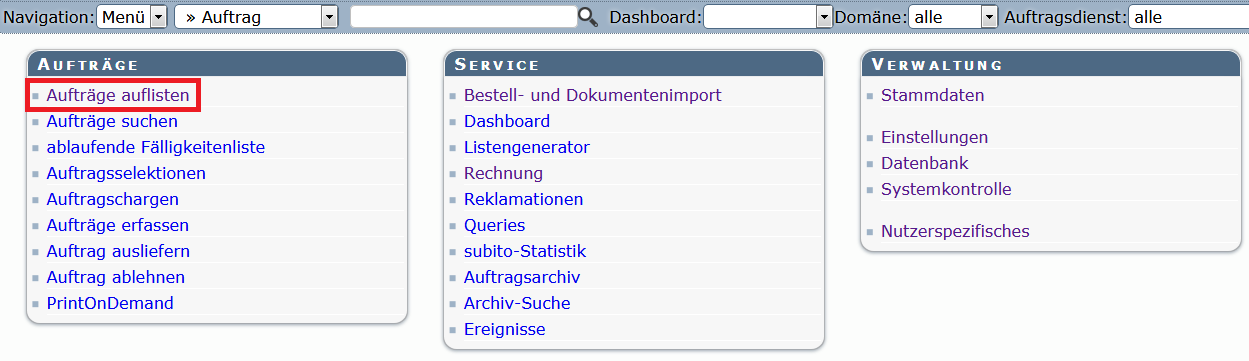
Es erscheint die Auftragsliste. Wählen Sie aus der Auftragsliste den Auftrag für den Sie den Import durchführen wollen und Klicken Sie auf das Icon ![]() .
.
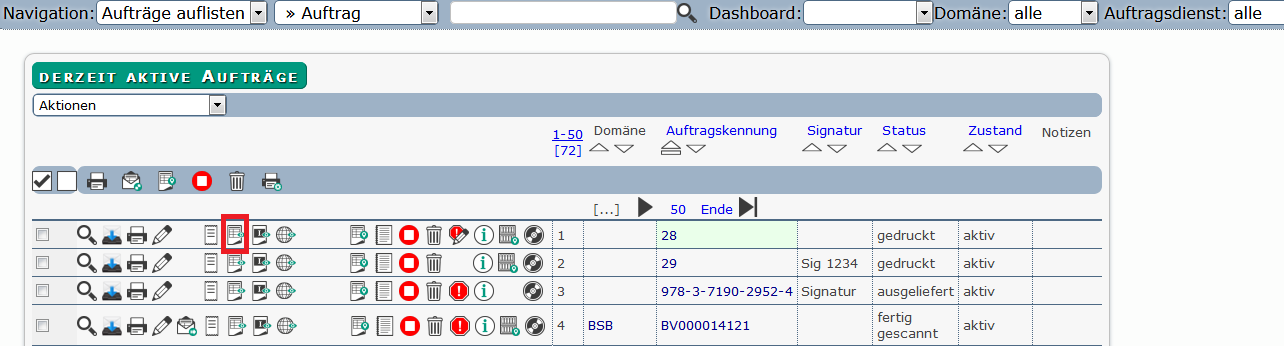
Sie erhalten die Auftragsvorschau des Auftrages.
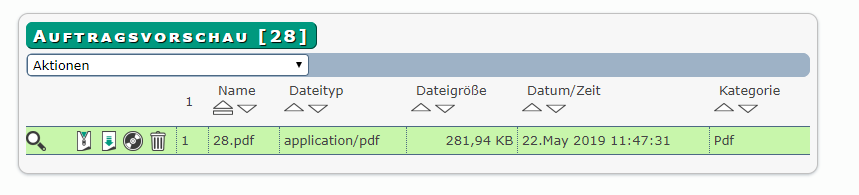
Dort klicken Sie auf Aktionen. Es öffnet sich ein Dropdown-Menü mit verschiedenen Auswahlmöglichkeiten. Sie wählen mit einem Klick der linken Maustaste Dokument importieren.
Sie erhalten ein Fenster mit folgender Aufforderung:

Sie klicken auf Datei auswählen und

laden die gewünschte Datei hoch.

Als weitere Optionen stehen Ihnen folgende Funktionen zu Verfügung.
- Anzahl der Seiten (optional, da das ganze Dokument ausgeliefert wird )
- Plausibilitätscheck (Dokument-Mimetype überprüfen ob PDF oder MTiff)
- Auslieferungsformat anpassen
- Dateiname anpassen
- Auftragsstatus anpassen
- existierende Dokumente nach Import löschen.
Haben Sie das gewünschte Dokument ausgewählt, klicken Sie auf Dokument importieren.
Nach erfolgreichem Import wird die Auftragsvorschau mit dem importierten Dokument angezeigt.
2.1.2 Importfunktion mit Seitenextraktion
Die Importfunktion mit Seitenextraktion eignet sich unter anderem für die Verarbeitung von eRessourcen. Dabei werden die Images nach dem Import extrahiert, eventuell vorhandene OCR entfernt und in Einzelimages abgelegt.
Für die Importportfunktion mit Seitenextraktion stehen zwei Aktionen in der Auftragsvorschau zur Verfügung:
- „PDF-Datei importieren und extrahieren“
- „MTiff-Datei importieren und extrahieren“
Gehen Sie hierzu nochmals zum Punkt Auftragsvorschau zurück.
Dort klicken Sie nochmals auf Aktionen. Es öffnet sich wiederum das Dropdown-Menü mit verschiedenen Auswahlmöglichkeiten. Sie wählen mit einem Klick der linken Maustaste PDF-Datei importieren und extrahieren oder MTiff-Datei importieren und extrahieren.
Bei Auswahl einer der beiden Aktionen öffnet sich jeweils folgende Seitenextraktionsmaske:
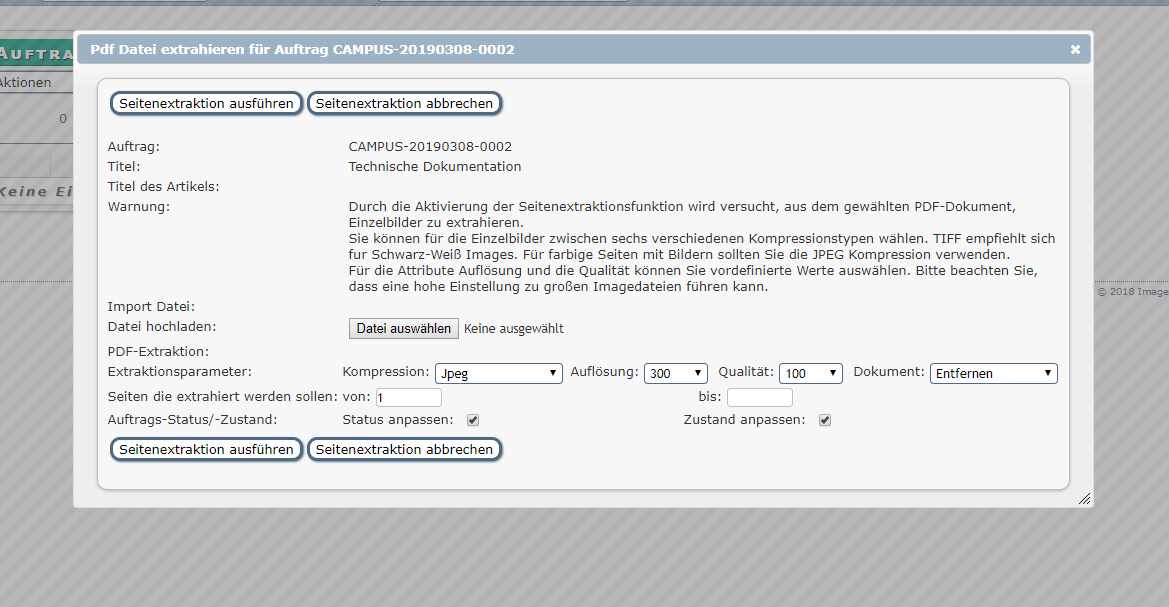
Hier können Sie die Art der Bildkompression, die Auflösung (dpi) und die Qualität (in Prozent) der zu erzeugenden Images festlegen.
Darüber hinaus können Sie festlegen, wie viele Seiten extrahiert werden sollen, ob das Original-Dokument entfernt oder behalten werden soll und ob Auftragsstatus bzw. -zustand angepasst werden soll. Die üblichen Einstellungen dabei sind
- Dokument entfernen
- Status anpassen
- Zustand anpassen nein
Bei Seiten die extrahiert werden sollen (von/bis) müssen Sie nur etwas eintragen wenn nicht alle Seiten des Dokuments extrahiert werden sollen, sonst erkennt MyBib eDoc die Anzahl der Seiten und extrahiert diese automatisch.
Anschließend wählen Sie die zu importierende Datei mit Datei auswählen aus und starten die Seitenextraktion mit Seitenextraktion ausführen.
In der Auftragsvorschau sind dann die zerlegten Images zu sehen
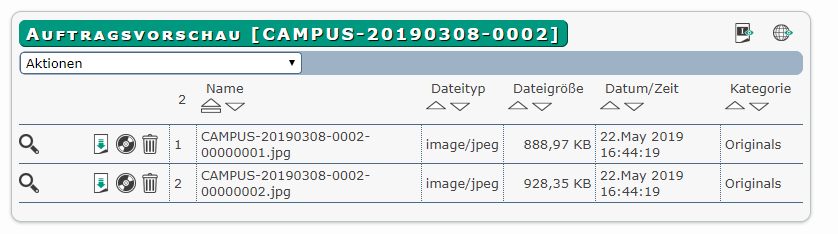
2.2 Automatischer ImportAbschnitt hinzufügen
Der automatische Import eignet sich unter anderem für die Übernahme von Dokumenten von anderen Liefersystemen oder Scanclients, die nicht die XML-RPC-Schnittstelle von MyBib eDoc nutzen. Der Import kann per Dateisystem (beispielsweise bei Nutzung des TIB-Indexformats) oder per FTP-Upload erfolgen.
Voraussetzung zum automatischen Import in bestehende Aufträge ist eine entsprechende Dokumentenressource bei der die Auftragserfassung unterdrückt ist und bei FTP-Upload als Importressource zusätzlich ein Transferziel des Typs Dateiressource.
Beachte: Damit die Scans von MyBib eDoc verarbeitet werden können muss der Linux-Nutzer, mit dem sich ein Client (Scanstation ohne BCS-2, FTP-Client) auf dem Server anmeldet, um Dateien in dem Importverzeichnis abzulegen, die selbe Nutzergruppen zugewiesen bekommen, in der sich auch MyBib eDoc befindet (meistens www-data). Ansonsten schlägt der automatische Import fehl.
Der automatische Import erfolgt über die Batch-Metaklasse „Dokumentenimport“ .
Wählen Sie das Einstiegsmenü.
Klicken Sie unter Menü in der Spalte Verwaltung auf Einstellungen.
Es erscheinen sämtliche Einstellungsmöglichkeiten. Klicken Sie auf Batchverwaltung.
Es erscheinen sämtliche Einstellungsmöglichkeiten der Batchverwaltung.
Klicken Sie auf Batch-Metaklassen.
Es erscheint eine Übersicht sämtlicher Batch-Metaklassen.
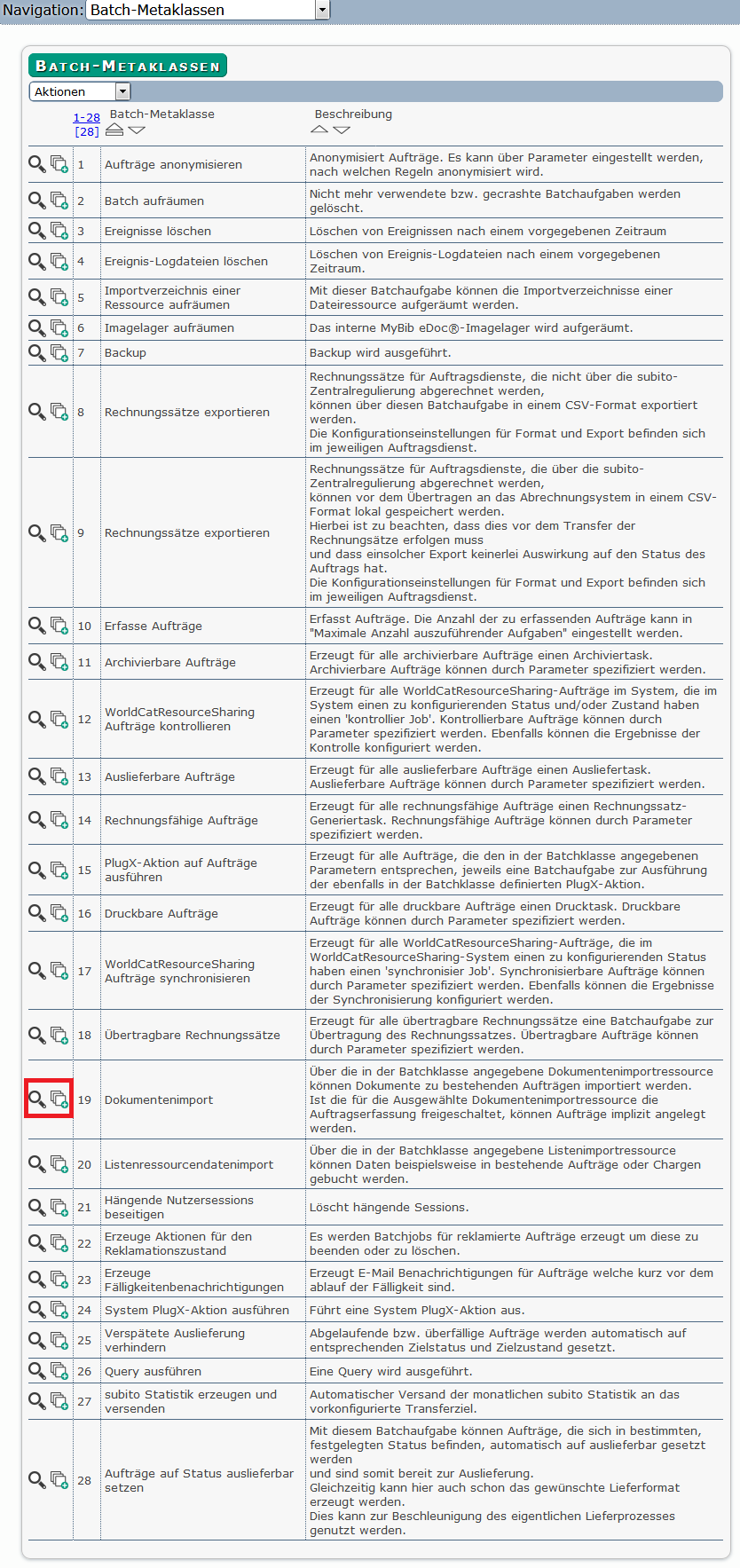
Möchten Sie jetzt eine neue Batchklasse erstellen, Klicken Sie in der Zeile Dokumentenimport auf das Icon ![]() .
.
Sie erhalten folgende Ansicht:
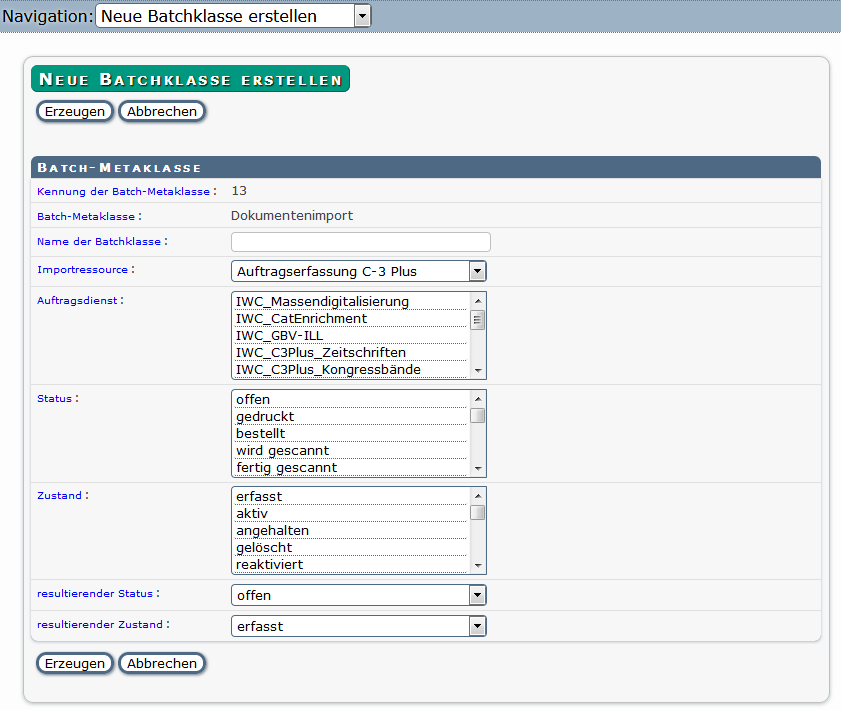
Nehmen Sie folgende Konfigurationen vor
- Tragen Sie einen Namen für die Batchklasse ein
- Wählen Sie die Importressource aus der Liste der angelegten Importressourcen aus. Achten Sie darauf, dass es eine Ressource ist, bei der Auftragserfassung unterdrückt ist
- Wählen Sie den Auftragsdienst aus für den die Batchklasse gelten soll, mehrere Dienste sind möglich
- Wählen den Status und den Zustand der Aufträge aus, die bei dem Batchdurchlauf berücksichtigt werden sollen
- Wählen den Status und den Zustand der Aufträge aus, die nach dem Batchdurchlauf automatisch von MyBib eDoc geändert werden.
Mit Erzeugen wir die Maske zum Einstellen des Batchintervalls geöffnet.
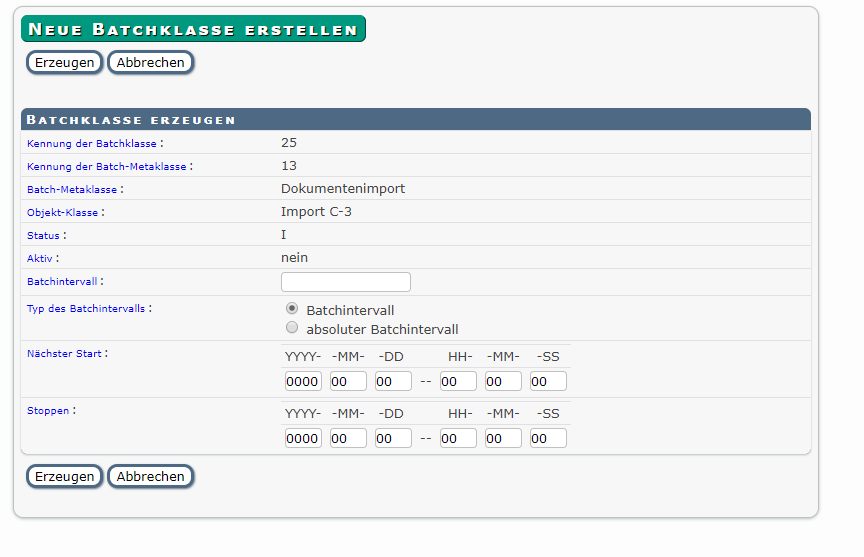
In dieser Maske tragen Sie einen Wert für das Batchintervall ein, also in welcher Regelmäßigkeit der Batch ausgeführt wird.
Die Notation ist angelehnt an die cron-Notation von posix-Systemen. Beispielsweise mm(2,10,30) heißt jede 2.,10. und 30.Minute .
Tragen Sie bei Nächster Start und Stoppen nur Werte ein wenn die Batchklasse zu einem bestimmten Zeitpunkt das erste Mal Starten bzw. Stoppen soll. Lassen die Felder leer wird die Batchklasse zum nächstmöglichen Zeitpunkt gestartet und gestoppt.
Mit Erzeugen wird die Batchklasse erstellt und wird anschließend in der Liste der angelegten Batchklassen aufgelistet.
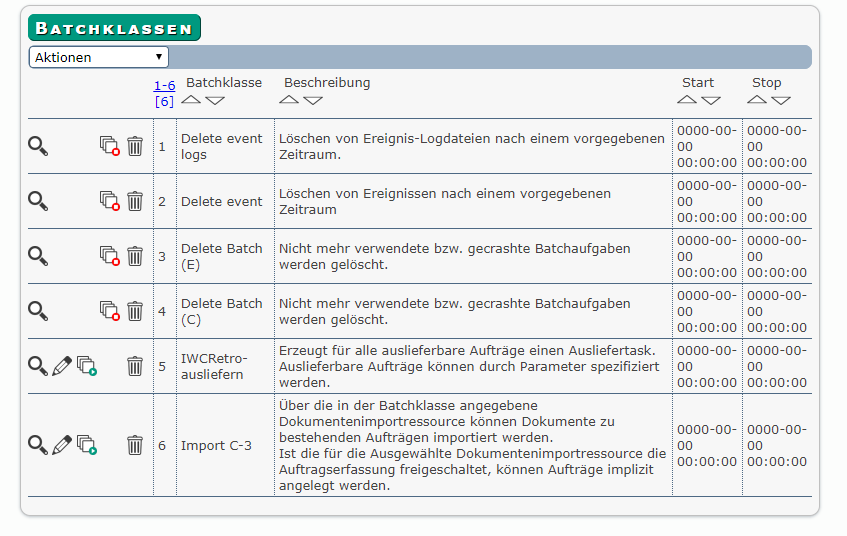

Die Batchklasse aktivieren Sie mit
Nach dem Import liegen die Dateien im Scanverzeichnis des entsprechenden Auftrags bereit. Dokumentenspezifische Einstellungen (Anzahl der Scans, Importflag, usw.) werden für den Auftrag angepasst. Die Reihenfolge der Erfassung der einzelnen Dateien erfolgt in alphabetischer Reihenfolge der Dateinamen.
2.3 Import mit AuftragserfassungAbschnitt hinzufügen
Beim Import mit Auftragserfassung muss die Erfassung der Aufträge in der Dokumentenressource freigegeben sein.
Dazu muss beim Anlegen der Ressource im Auswahlmenü für den Subtyp des Peers „Auftragserfassung freigegeben“ ausgewählt werden.
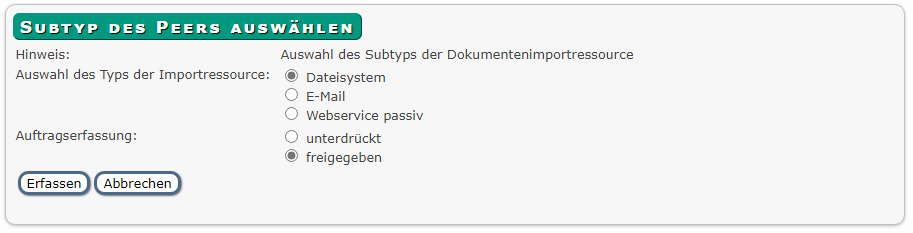
Die Einstellung entspricht dann dem automatischen Import ohne Auftragserfassung.