

12. Menu OCRadd chapter
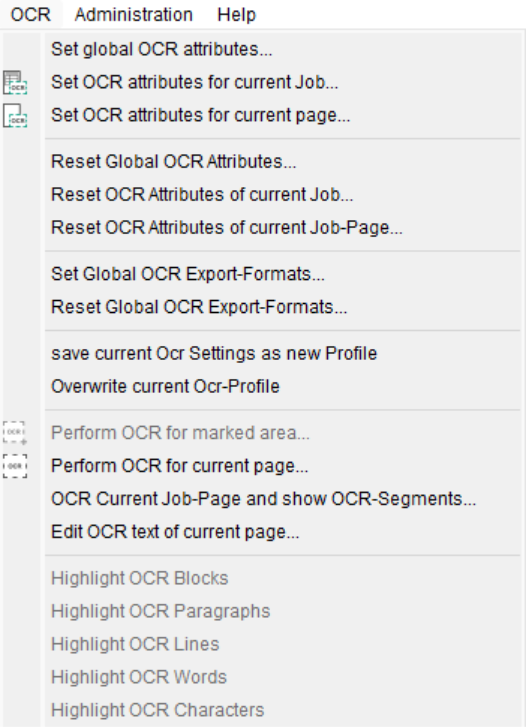
12.1 OCR Attributesadd section
Depending on the OCR engine used (ABBYY or Tessseract), you specify the OCR attributes that BCS-2 uses to process an image.
Set global OCR attributes: BCS-2 always uses this configuration when no job or page-specific settings are made or the OCR settings are controlled by the job index.
 Set OCR attributes for current Job: BCS-2 uses the configuration for the OCR processing of the current job.
Set OCR attributes for current Job: BCS-2 uses the configuration for the OCR processing of the current job.
 Set OCR attributes for current page: BCS-2 uses the configuration only for OCR processing of the current page.
Set OCR attributes for current page: BCS-2 uses the configuration only for OCR processing of the current page.
Reset global OCR attributes: BCS-2 resets the OCR attributes to the application’s original default values.
Reset OCR Attributes of current Job: BCS-2 resets the OCR attributes to the global settings.
Reset OCR Attributes of current Job-Page: Resets the OCR attributes to the job-specific or global settings.
12.2 Configure OCR Attributesadd section
Since the OCR engines offer a wide range of configuration options, use the drop-down list below the “OCR attributes” to select an experience level (beginner, intermediate, expert). This is how you limit the number of configuration options.
The attributes for the OCR engines are preconfigured, so you usually only need to specify the language and, in the case of ABBYY, the font.
If you do not select the correct font and language, the result of the OCR will be correspondingly poor.
{kind=link}
Tesseract
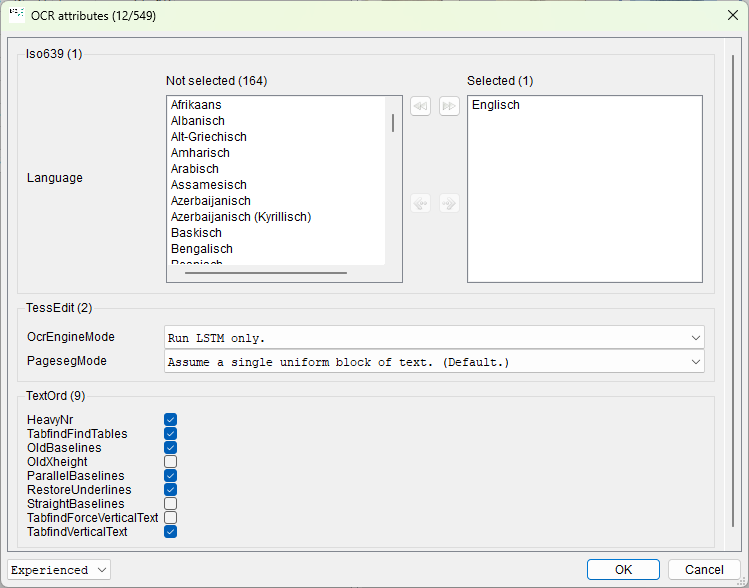
When configuring Tesseract, note that "Run LSTM only." is selected as "OcrEngineMode". In addition, in the OCR settings for the workflow, activate the mode "when performing OCR for the whole page: keep the resulting OCR-Doc-Object for later use (zoned OCR...)".
12.3 OCR Profilesadd section
OCR attributes that were set for a job can be saved as an OCR profile and can therefore be used in other jobs.
To do this select “save current OCR Settings as new Profile” after selecting and confirming the “OCR attributes for the current job”.
A dialogue box will appear in which you can enter a name and settings for the profile.
save current OCR Settings as new Profile: BCS-2 saves the ‘Set OCR Attributes for the current Job..’ settings as a new OCR profile. This allows you to save OCR settings for different workflows and jobs. Enter the name of the new profile and a description
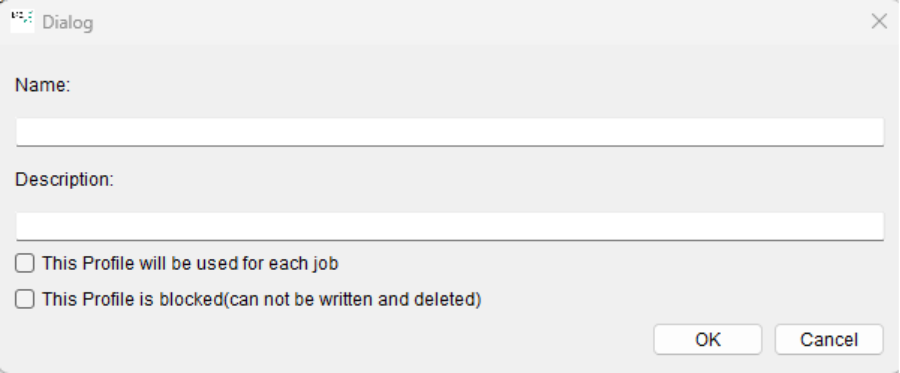
- This profile will be used for each scan: when this function is activated and the profile attached to the workflow, the user can’t change the scanner settings in the job. They will always be reset to the profile settings.
- This profile is blocked (can not be written or deleted): The user can`t change or delete the profile, it has to be deleted via the OCR Profile tab.
Confirm your entry with “OK”. The new scan profile is now available to you via the drop-down list in the toolbar and in the workflow configuration (tab Basic)
12.4 Perform OCRadd section
 Perform OCR for marked area: BCS-2 only performs text recognition for the selected area on the image.
Perform OCR for marked area: BCS-2 only performs text recognition for the selected area on the image.
 Perform OCR for current page: BCS-2 carries out the text recognition for the entire page.
Perform OCR for current page: BCS-2 carries out the text recognition for the entire page.
OCR Current Job-Page and show OCR-Segments: BCS-2 performs text recognition for the entire page and then displays the segments (areas) recognized by the OCR engine.
Edit OCR text of current page: Calls the text editor to correct or copy the OCR full text.
12.5 Zoned OCRadd section
The function “zoned OCR to clipboard” is available in the context menu of the viewer for the direct transfer of texts to the clipboard.
With this technique it is easy to generate OCR data and assign corresponding objects (nodes) or indices:
- In the structure tree: Right-click on the respective node and select “Insert text from ClipBoard”.
- In the job index: Transfer to the last active field.
- Anywhere: Select the element and use CONTROL-V to insert the text content of the clipboard.
12.6 Speech output of OCR textsadd section
BCS-2 reads OCR texts aloud.
Voice output is possible at the following points:
- Zoned OCR to clipboard: Press CTRL while dragging, then BCS-2 will read the text.
- OCR editor (OCR result dialog): There is a corresponding button that opens the text-to-speech dialog.
- OCR editor (displayed): There is a corresponding button that opens the text-to-speech dialog.
In the open text-to-speech dialog, it is possible to change the language, provided it has been installed in the respective Windows system.
Furthermore, the text itself can also be changed, i.e. you can insert any texts via copy and paste in the open text-to-speech dialog as a test, in order to output texts in other languages via the speech function.
12.7 OCR additional functionsadd section
The additional OCR functions are only available after a successful OCR run.
Highlight OCR Blocks: Displays blocks recognized by the OCR on the image.
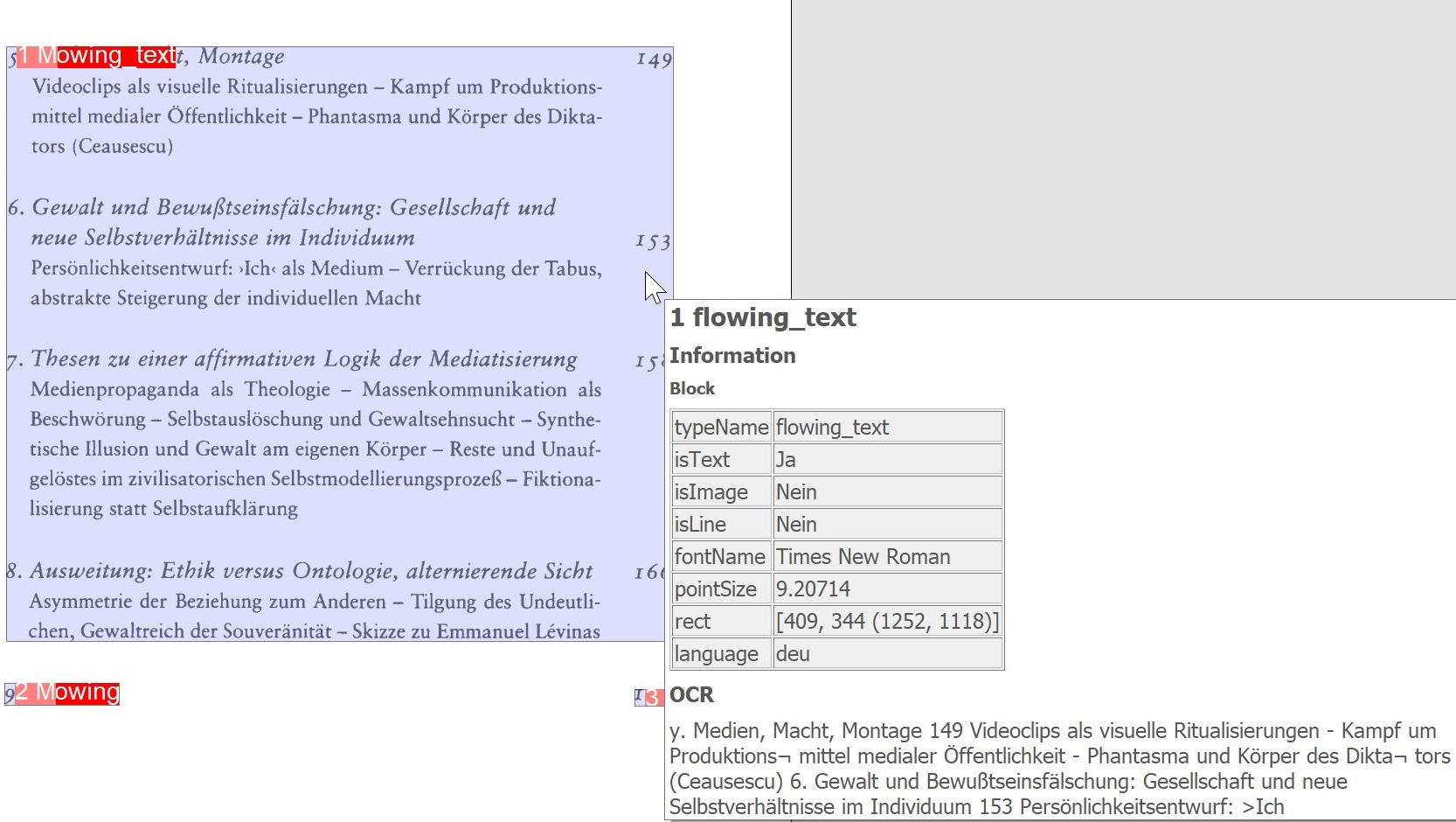
Highlight OCR Paragraphs: Displays paragraphs recognized by the OCR on the image.
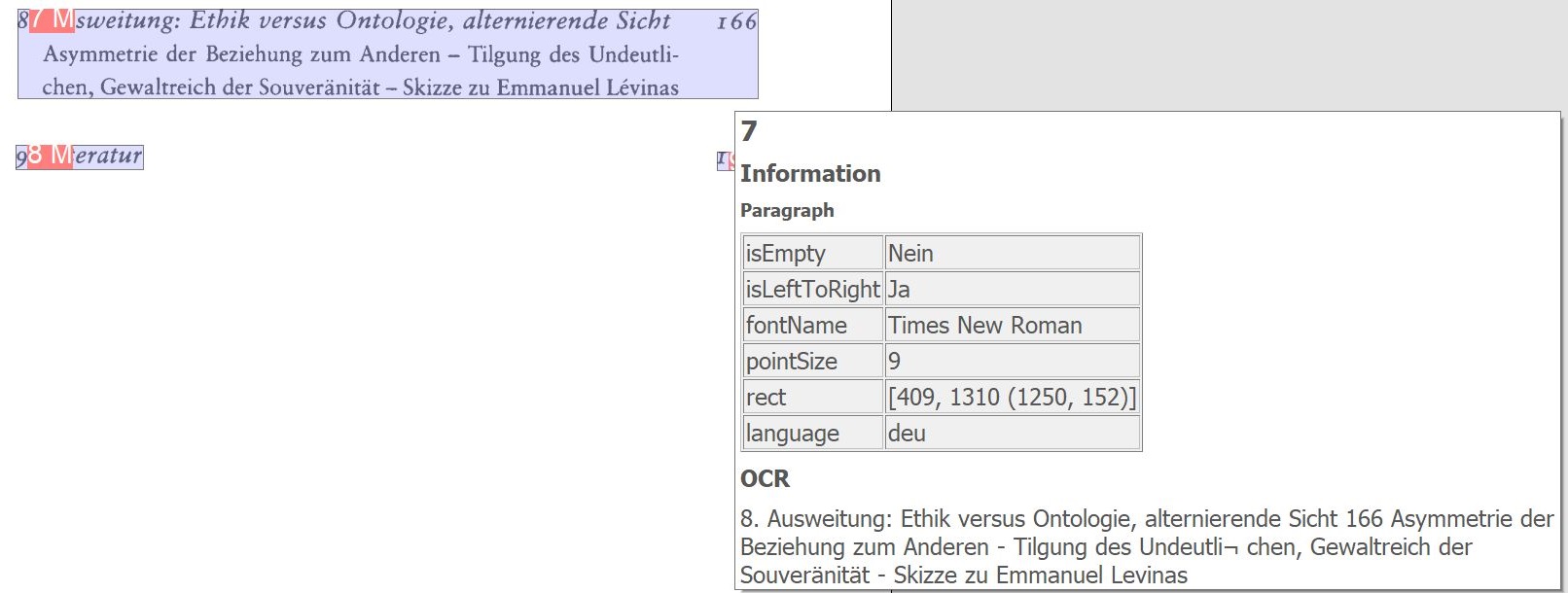
Highlight OCR Lines: Displays lines of text recognized by the OCR on the image.
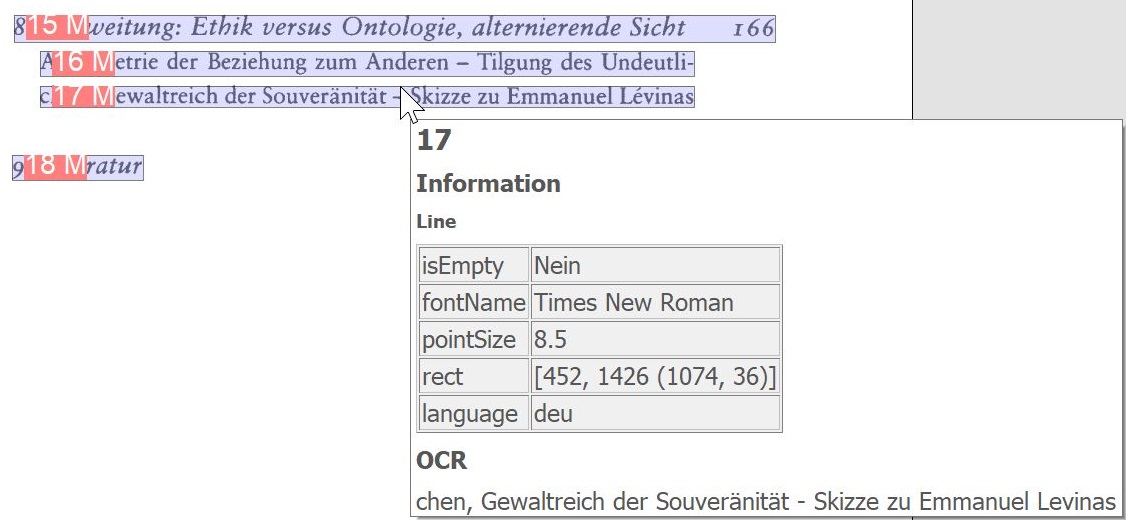
Highlight OCR words: Displays words recognized by the OCR.
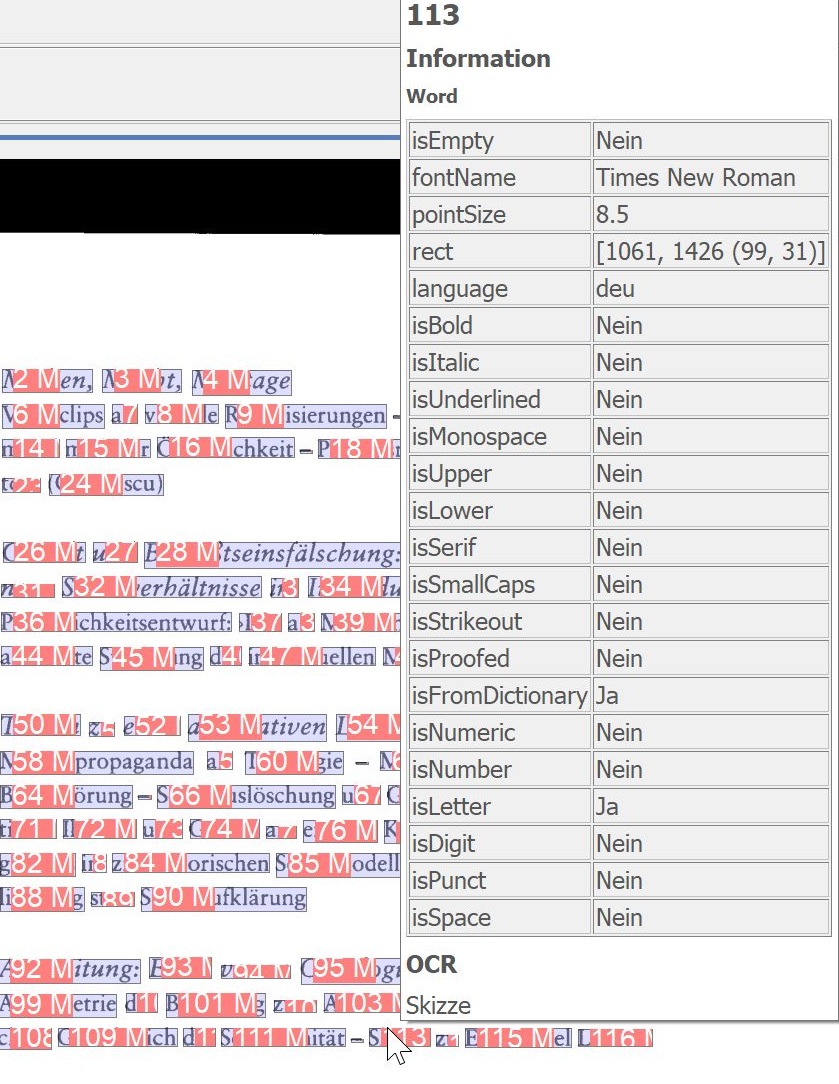
The following applies to all additional OCR functions: With a mouseover over the marked areas, BCS-2 displays the determined OCR information.
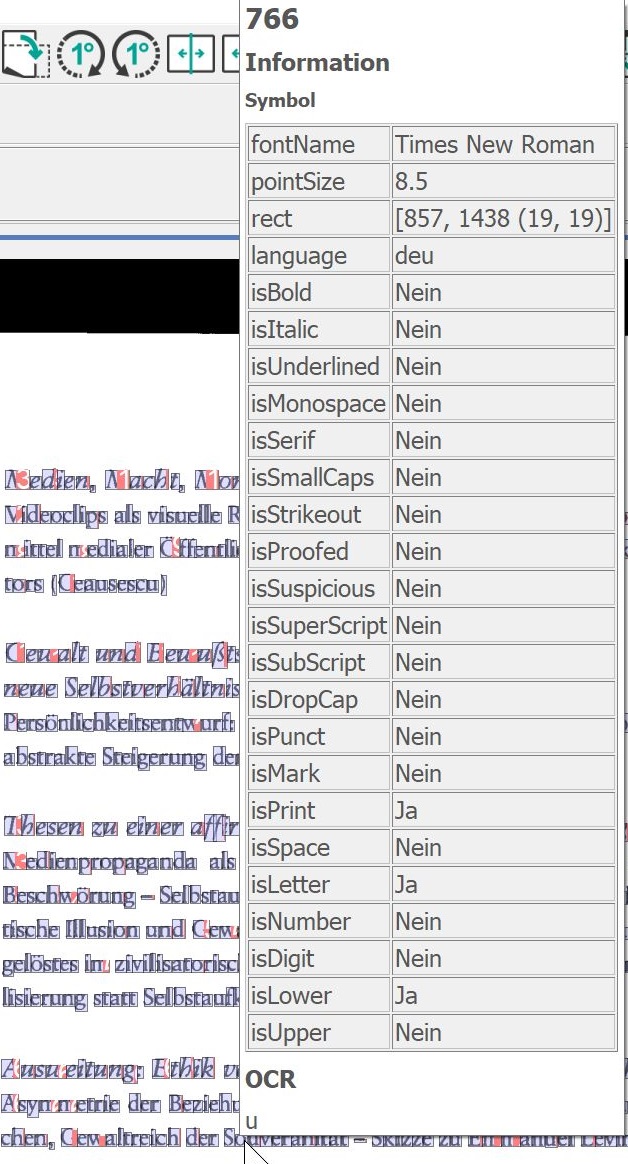
Highlight OCR Characters: Highlights all symbols and letters recognized by the OCR.
Search in OCR texts: The prerequisite is that the OCR text is available in IWC-DOK format. This is the case with OCR texts that you generate via the shortcut “O” or via the “Job” menu > “Execute operations on the job”. You can open the search form by clicking on the shortcut “ctrl + F”.
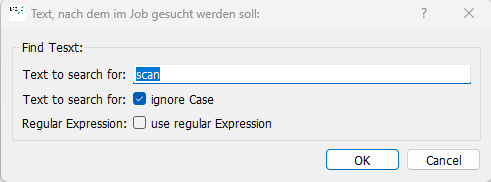
BCS-2 marks the matching entries found in yellow:

12.8 Remove OCR Breaksadd section
If the OCR recognizes breaks, then these are usually also contained in the OCR text.
However, this does not apply if the OCR text is subsequently fetched from the internally available IW OcrDoc object:
Only the word list is searched in this case and all words belonging to an area are returned, separated by blanks.
It depends on the way the specific OCR text is obtained in the application.
If it is fetched by direct OCR, i.e. without the IW-OcrDoc (by a direct ABBYY run), then the breaks are present.
Adjustments concerning release 6.4.6:
- If an OCR text from an area is assigned to an index using the area properties dialog, line breaks are replaced by spaces.
A general removal of breaks does not make sense.
What else can be done:
If OCR results are used in scripts, you can make the appropriate substitutions in the script.
Example:
If the script variable “str” contains a character string that also contains breaks, these can be removed by using str.replace(„\n“, “ „).
Instead of the expression str, use str.replace(“\n”, ” “).